概述
什么是Kubernetes
Kubernestes简称K8S,是由Google开源的容器引擎编排工具。可以高效、快速实现应用部署、高可用的实现。
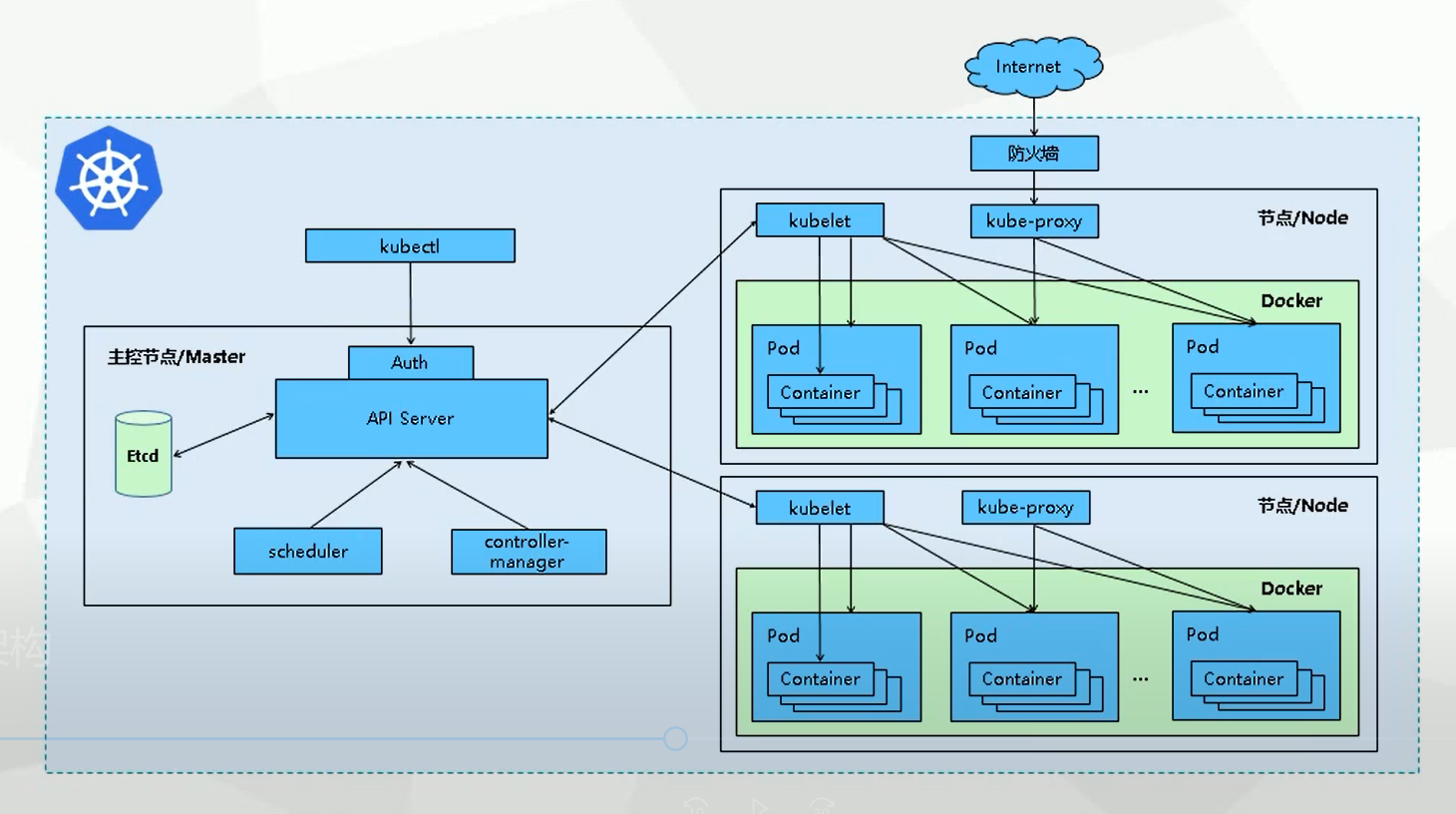
k8s架构
从k8s架构图可以看出,主要分为两种节点:Master、Node
Master:运行kube-api、kube-controller-manager、kube-scheduler、etc等组件实现k8s资源的调度、健康检查等。Node:运行kube-proxy、kubelet主要实现k8s Pod、Service的生命周期管理。
k8s基本概念
Pod:是k8s最小的调度单位,一个Pod可以包含一个或多个容器。k8s通过Pod来管理容器。Node:k8s集群中的工作节点,用来管理运行在Node节点上的容器、容器网络等资源。Namespace:用来隔离k8s集群中提供的资源。不同的namespace相互隔离无法访问。Service:Pod的网络实现,由kube-proxy组件将服务IP负载均衡到Pod的endpoints上。Label:识别kubernetes对象资源的标签,以key/value的方式附加到资源对象上。需要配合标签选择器来实现。Label Selector:支持等式(app=nginx)、集合(env inproduction)这两种方式。比如给Node节点设置app=nginx标签,创建Pod的时候使用等式标签选择器,让其调度到app=nginx的节点。Annotations:注解。Replication Controller:简称RC,Pod副本控制器。通过监控运行中Pod来保证集群中运行指定数量的Pod副本。ReplicaSet:简称RS,和RC的功能一样都是用来实现管理Pod副本。通过管理ReplicaSet的Deployment对象来控制副本。这是因为Deployment提供了更高级别的功能,如滚动更新和回滚等,这些功能使得应用部署和管理更加便捷和可靠。Deployment:无状态Pod副本控制器,调用ReplicaSet管理Pod副本。StatefulSet:用来部署有状态服务,比如:数据库、缓存等需要持久化存储数据的中间件或服务。DaemonSet:和Deployment一样都是用来部署Pod,区别在于Deployment只在一个或多个节点部署Pod,而DaemonSet在k8s集群每个Node节点部署一个pod。Service:Pod网络的实现。Job:k8s用来控制批处理型人物的API对象。Volume:k8s集群的存储卷和Docker的存储卷类似,不过Docker存储卷作用范围为一个容器,而k8s的存储卷的生命周期和作用范围是一个Pod。每个Pod中声明的存储卷由Pod中的所有容器共享。Persistent Volume Claim:简称PVC,PV和PVC的关系:PVC提供配置持久化存储,PV提供持久化存储。Secret:用来保存密码、密钥、认证凭证等敏感的对象。Service Account:为了方便Pod里面的进程调用Kubernetes API或其他外部服务而设计的。- RBAC:Role-based Access Control简称RBAC,是k8s集群中基于角色的访问控制。
k8s核心组件
kube-api
提供集群管理的 REST API 接口,包括认证授权、数据校验以及集群状态变更等。提供其他模块之间的数据交互和通信的枢纽。
其他组件对资源对象的增、删、改、查和监听操作都是交由api-server处理后,api-server再提交给etcd数据库做持久化存储,只有api-server才能直接操作etcd数据库,其他组件都不能直接操作etcd数据库,其他组件都是通过api-server间接的读取,写入数据到etcd。
Etcd
etcd是一个分布式的键值对存储数据库,主要是用于保存k8s集群状态数据,比如,pod,service等资源对象的信息;
kube-controller-manager
k8s中各种控制器的的管理者,是k8s集群内部的管理控制中心,也是k8s自动化功能的核心;controller-manager内部包含deployment控制器、replicaSet控制器、statefulset控制器、daemonset控制器、job控制器、cronjob控制器、node控制器、endpoint控制器等等各种资源对象的控制器,每种控制器都负责一种特定资源的控制流程,而controller-manager正是这些controller的核心管理者。
kube-scheduler
主要负责整个集群资源的调度功能,根据特定的调度算法和策略,将Pod调度到最优的工作节点上面去,从而更加合理、更加充分的利用集群的资源,这也是我们选择使用 kubernetes 一个非常重要的理由。
kube-scheduler调度工作主要分为以下两个部分:
- Predicates预选阶段:首先遍历所有节点,过滤掉不满足条件的节点。如果所有节点都不满足过滤条件那么Pod会一直处于Pending状态,直到有节点满足条件。
- Priorities优选阶段:再次对节点进行筛选,如果有多个节点都满足条件,那么kube-scheduler会根据优先级对节点进行排序,最终调度Pod到优先级最高的节点。在优选阶段期间,Pod 的状态并不会改变,它依然是
Pending,一旦 Pod 成功绑定到一个节点,它的状态会从Pending变更为Running或者其他状态。
Predicates预选阶段算法:
| 调度策略/检查项 | 描述 |
|---|---|
| PodFitsResources | 节点可用资源是否满足创建Pod请求的资源 |
| PodFitsHost | 如果Pod指定了NodeName,检查节点名称是否和NodeName匹配 |
| PodFitsHostPorts | 节点上已经使用的port是否和Pod申请的 port 冲突 |
| PodSelectorMatches | 过滤掉和Pod指定的label不匹配的节点 |
| NoDiskConflict | 已经mount的volume和Pod指定的volume不冲突,除非它们都是只读的 |
| CheckNodeDiskPressure | 检查节点磁盘空间是否符合要求 |
| CheckNodeMemoryPressure | 检查节点内存是否够用 |
Priorities优先阶段算法:
| 调度策略/优先级 | 描述 |
|---|---|
| LeastRequestedPriority | 通过计算CPU和内存的使用率来决定权重,使用率越低权重越高 |
| SelectorSpreadPriority | 对同属于一个Deployment或者RC下面的多个Pod副本,尽量调度到多个不同的节点上 |
| ImageLocalityPriority | 如果在某个节点上已经有要使用的镜像了,镜像总大小值越大,权重就越高 |
| NodeAffinityPriority | 根据节点的亲和性来计算一个权重值 |
自定义调度策略
kube-scheduler在启动的时候可以通过 --policy-config-file参数来指定调度策略文件,文件内容如下:
{ |
Kubelet
每个node节点上都有一个kubelet服务进程,默认监听 10250 端口,负责维护pod和容器的生命周期,当监听到master下发到本节点的任务时,比如创建、更新、终止pod等任务,kubelet 即通过控制docker来创建、更新、销毁容器;
kubelet还会定时执行pod中容器定义的探针,然后根据容器重启策略执行对应的操作。每个kubelet进程都会在api-server上注册本节点自身的信息,用于定期向master汇报本节点资源的使用情况。
kubelet的功能:
节点管理:kubelet启动时会向api-server进行注册,然后会定时的向api-server汇报本节点信息状态,资源使用状态等。POD管理:kubelet负责维护node节点上pod的生命周期,当kubelet监听到master的下发到自己节点的任务时,比如要创建、更新、删除一个pod,kubelet 就会通过CRI(容器运行时接口)插件来调用不同的容器运行时来创建、更新、删除容器;常见的容器运行时有docker、containerd。容器健康检查:pod中可以定义启动探针、存活探针、就绪探针等3种,我们最常用的就是存活探针、就绪探针,kubelet 会定期调用容器中的探针来检测容器是否存活,是否就绪,如果是存活探针,则会根据探测结果对检查失败的容器进行相应的重启策略;Metrics Server资源监控:在node节点上部署Metrics Server用于监控node节点、pod的CPU、内存、文件系统、网络使用等资源使用情况,而kubelet则通过Metrics Server获取所在节点及容器的上的数据。
Kube-proxy
kube-proxy是Kubernetes的一个组件,它是一个网络代理,用于实现Kubernetes集群中Service和Pod之间的网络通信。主要作用是将Kubernetes Service中定义的虚拟IP地址和端口转发到集群中的Pod,以实现服务的访问。
kube-proxy支持以下几种实现:
- userspace:最早的负载均衡方案,在用户空间监听一个端口,所有服务通过iptables转发到这个端口,然后在其内部负载均衡到实际的Pod。这种方式主要的问题是效率低,有性能瓶颈。
- iptables:目前推荐的方案,以iptables规则的方式来实现service负载均衡。该方式主要的问题是在服务多的时候产生太多的iptables规则,非增量式更新会引入一定的延迟,大规模情况下有性能的问题。
- ipvs:为解决iptables模式的性能问题,v1.11新增了ipvs模式,采用增量式更新,并可以保证service更新期间保持不断开。
- winuserspace:同userspace,仅工作在windows节点。
注意:使用ipvs模式时,需要预先在每台Node上加载内核模块nf_conntrack_ipv4、ip_vs、ip_vs_rr、ip_vs_wrr、ip_vs_sh等。
# load module <module_name> |
资源对象
HPA
Horizontal Pod Autoscaling简称HPA,可以根据CPU使用率或应用自定义metrics自动扩展Pod数量。支持replication controller、deployment和replica set。
HPA特点:
- 控制管理器每隔30s查询metrics的资源使用情况,可通过–horizontal-pod-autoscaler-sync-period参数修改。
- 支持三种metrics类型。
- 预定义metrics以利用率的方式计算,如:Pod的CPU。
- 自定义的Pod metrics的方式计算。
- 自定义的object metrics。
- 支持两种metrics查询方式:Heapster和自定义的REST API。
- 支持多种metrics。
Configmap
创建configmap
key/value字符串创建
#创建 |
env文件创建
echo -e "a=b\nc=d" | tee config.env |
目录创建
mkdir config |
yaml/json文件创建
apiVersion: v1 |
kubectl create -f config.yaml |
CronJob
CronJob 即定时任务,就类似于 Linux 系统的 crontab,在指定的时间周期运行指定的任务。
CronJob Spec
- .spec.schedule:指定任务运行周期,格式同cron
- .spec.jobTemplate:指定需要运行的任务,格式同Job
- .spec.startingDeadlineSeconds:指定任务开始的截止期限
- .spec.concurrencyPolicy:指定任务的并发策略,支持Allow、Forbid和Replace三个选项
使用方式
创建一个cronjob
apiVersion: batch/v1 |
查看cronjob
$kubectl get cronjob |
查看jobs
$kubectl get jobs |
DaemonSet
保证每个Node节点上都运行一个Pod副本,通常用来部署一些集群日志、监控或其他应用。
滚动更新
v1.6+支持DaemonSet的滚动更新,可以通过.spec.updateStrategy.type设置更新策略,目前支持两种策略:
- OnDelete:默认策略,更新模板后,只有手动删除了旧的Pod后才会创建新的Pod。
- RollingUpdate:更新DaemonSet模板后,自动删除旧的Pod并创建新的Pod。
在使用RollingUpdate策略时,还可以设置:
.spec.updateStrategy.rollingUpdate.maxUnavailable,默认1spec.minReadySeconds,默认0
回滚
v1.7+还支持回滚
# 查询历史版本 |
Deployment
deployment是kubernetes中无状态控制器,使用RS为Pod提供声明式部署。
创建deployment
将kubectl的–record的flag设置为true,可以在annotation中记录当前命令创建或升级了该资源。例如查看每个deployment revision中执行了哪些命令
kubectl create -f xxx.yaml --record |
执行以下命令可以看到创建的rs
kubectl get rs |
更新deployment
如果要更新deployment的pod的image,使用以下命令
kubectl set image deployment/<deployment_name> nginx=nginx=1.9.1 |
也可以使用edit命令编辑deployment修改image为1.9.1
kubectl edit deployment/<deployment_name> |
回退deployment
如果想要回退某个deployment,默认情况下kubernetes会在系统中保留所有的deployment的rollout历史记录,方便随时回退。可以修改revision hostory limit来更改保存的revision数。
只要deployment的rollout被处罚就会传教概念一个revision。也就是说当deployment的pod template被更新,就会创建一个新的revision。
如果扩容deployment不会创建revision,当你回退到历史revision时,只有deployment中的pod template才会回退。
deployment历史记录
查看deployment历史记录
kubectl rollout history deployment/nginx-deployment |
查看某个revision的详细记录
kubectl rollout history deployment/nginx-deployment --revision=2 |
回退到历史版本
使用以下命令可以回退到历史记录,使用--to-revision=2参数指定某个历史记录。
kubectl rollout undo deployment/nginx-deployment --to-revision=2 |
清理Policy
可以通过设置.spec.revisionHistoryLimit来指定deployment最多保留多少revision历史记录。默认会保留所有的revision,如果设置为0,deployment不允许回退。
deployment扩容
使用以下命令进行扩容
kubectl scale deployment nginx-deployment --replicas 10 |
如果集群中启用了HPA,可以给deployment设置一个autoscaler,基于当前pod的cpu利用率选择最少和最多的pod数
kubectl autoscale deployment nginx-deployment --min=10 --max=15 --cpu-percent=80 |
比例扩容deployment
RollingUpdate Deployment支持同时运行一个应用的多个版本,当你autoscaler扩容一个正在rollout中的RollingUpdate Deployment的时候,为了降低风险Deployment Controller将会平衡已存在的active的ReplicaSets和新加入的replicas,被称为比例扩容。
暂停或恢复deployment
暂停deployment
kubectl rollout pause deployment/nginx-deployment |
恢复deployment
kubectl rollout resume deploy nginx |
deployment状态
- Progressing:正在创建、扩容、缩容一个
ReplicaSet。 - Complete:正常的deployment。
- Failed:镜像拉去错误、Pod运行错误、权限不足等。
Ingress
通常情况下service和pod的ip只能在k8s集群内部访问,集群外部的请求需要通过负载均衡转发到service在node上保留的NodePort上,然后再由kube-proxy通过边缘路由器将其转发给相关的pod。而Ingress就是为进入集群的请求提供路由规则的集合。
Ingress可以给service提供集群外部访问的URL、负载均衡、SSL、HTTP路由等。为了配置这些Ingress规则,集群管理员需要部署一个Ingress Controller,监听Ingress和service的变化,并根据规则配置负载均衡提供访问入口。
Ingress类型
- 单服务
Ingress:一个Ingress只有一个后端Pod - 多服务
Ingress:一个Ingress下挂载多个Pod,根据访问Ingress的路径转发到不同的Pod。比如:访问/aaa转发到aaa Pod,访问/bbb转发到bbb Pod。 - 虚拟主机
Ingress:访问aaa.acaiblog.top转发到aaa Pod,访问bbb.acaiblog.top转发到bbb Pod。 - TLS Ingress:通过https证书实现应用https访问。
Resource Quotas
资源配额Resource Quotas时用来限制用户资源用量的一种机制,应用在Namespace上,并且每个Namespace只能有一个ResourceQuota对象。
开启计算资源配额后创建容器必须配置计算资源请求或限制,用户超额后禁止创建新的资源。
资源配额类型
| 资源项 | 资源类型 | 描述 |
|---|---|---|
| cpu | 计算资源 | CPU核心数 |
| limits.cpu | 计算资源限制 | CPU使用上限 |
| requests.cpu | 计算资源请求 | CPU请求量 |
| memory | 计算资源 | 内存大小 |
| limits.memory | 计算资源限制 | 内存使用上限 |
| requests.memory | 计算资源请求 | 内存请求量 |
| requests.storage | 存储资源 | 存储资源总量 |
| persistentvolumeclaims | 存储资源对象 | PVC个数 |
| .storageclass.storage.k8s.io/requests.storage | 存储资源限制(指定StorageClass) | 指定storage class的存储资源总量 |
| .storageclass.storage.k8s.io/persistentvolumeclaims | 存储资源对象(指定StorageClass) | 指定storage class的PVC个数 |
| requests.ephemeral-storage | 存储资源 | 临时存储资源请求量(v1.8+) |
| limits.ephemeral-storage | 存储资源限制 | 临时存储资源使用上限(v1.8+) |
| pods | 对象数 | 可创建的Pod个数 |
| replicationcontrollers | 对象数 | 可创建的ReplicationController个数 |
| configmaps | 对象数 | 可创建的ConfigMap个数 |
| secrets | 对象数 | 可创建的Secret个数 |
| resourcequotas | 对象数 | 可创建的ResourceQuota个数 |
| persistentvolumeclaims | 对象数 | 可创建的PVC个数 |
| services | 对象数 | 可创建的Service个数 |
| services.loadbalancers | 对象数(服务类型) | 可创建的LoadBalancer类型的Service个数 |
| services.nodeports | 对象数(服务类型) | 可创建的NodePort类型的Service个数 |
计算资源
apiVersion: v1 |
对象个数
apiVersion: v1 |
开启资源配额
在kube-api启动时使用 --admission-control=ResourceQuota参数,然后在namespace中创建一个ResourceQuota对象。
LimitRange
默认情况下,Kubernetes 中所有容器都没有任何 CPU 和内存限制。LimitRange 用来给Namespace 增加一个资源限制,包括最小、最大和默认资源。例如:
apiVersion: v1 |
Service
Service是对一组提供相同功能的·Pods·的抽象,并为他们提供统一的入口。·Service·通过标签来选取服务后端,一般配合Replication Controller或者Deployment来保证后端容器的正常运行。
这些匹配的标签的Pod IP和端口列表组成endpoints,由kube-proxy负责将服务IP负载均衡到这些endpoints上。
Service的四种类型
ClusterIP:默认类型,子弟哦那个分配一个仅cluster内部可以访问的虚拟IPNodePort:在ClusterIP基础上为Service在每台机器上绑定一个端口,这样就可以通过IP+端口访问应用服务。LoadBalancer:在NodePort的基础上,借助cloud provider创建一个外部的负载均衡器,将请求转发到Node IP:NodePort上ExternalName:将服务通过DNS CNAME记录方式转发到指定的域名,需要kube-dns版本在1.7以上。
协议
Service、Endpoints、Pod支持三种类型的协议:TCP、UDP、STCP
ServiceAccount
Service Account是为了方便Pod里面的进程调用Kubernetes API或其他外部服务而设计的。与User Account不同。
- User Account是为用户设计,而Service Account为Pod中的进程调用Kubernetes API设计。
- User Account是跨namespace的,而Service Account仅限它所在的namespace。
- 每个namespace都会自动创建一个default service account。
- Token Controller检测Service Account的创建,并为他们创建secret。
授权
Service Account 为服务提供了一种方便的认证机制,但它不关心授权的问题。可以配合RBAC来为 Service Account 鉴权:
- 配置
--authorization-mode=RBAC和--runtime-config=rbac.authorization.k8s.io/v1alpha1 - 配置
--authorization-rbac-super-user=admin - 定义 Role、ClusterRole、RoleBinding 或 ClusterRoleBinding
示例:
# This role allows to read pods in the namespace "default" |
StatefulSet
StatefulSet是有状态控制器,使用场景如下所示:
- 持久化存储:Pod 重新调度后还是能访问到相同的持久化数据,基于 PVC 来实现
- 网络标志:Pod 重新调度后其 PodName 和 HostName 不变,基于 Headless Service(即没有 Cluster IP 的 Service)来实现。
更新StatefulSet
v1.7+支持StatefulSet的自动更新,通过spec.updateStrategy设置更新策略。目前支持以下两种更新策略:
OnDelete:当
.spec.template更新时,并不立即删除旧的 Pod,而是等待用户手动删除这些旧 Pod 后自动创建新 Pod。这是默认的更新策略,兼容 v1.6 版本的行为RollingUpdate:当
.spec.template更新时,自动删除旧的 Pod 并创建新 Pod 替换。在更新时,这些 Pod 是按逆序的方式进行,依次删除、创建并等待 Pod 变成 Ready 状态才进行下一个 Pod 的更新。
k8s访问控制
Kubernetes对API访问提供了三种安全访问控制措施:
- 认证:认证用户
- 授权:认证用户权限
Admission Control:主要负责资源管理
认证
Kubernetes集群开启TLS时,所有请求都需要先认证。Kubernetes支持多种认证机制,并支持同时开启多个认证插件,只要有一个插件认证通过即可。
如果认证成功,则用户的username会传入授权模块做授权验证。否则返回401错误。
目前Kubernetes支持以下认证插件:
X509证书- 静态
Token文件 - 引导
Token - 静态密码文件
Service AccountOpenIDWebhook- 认证代理
Openstack Keystone密码
RBAC授权
Kubernetes从1.6开始支持基于角色的访问控制机制(Role-Based Access,RBAC),集群管理员可以对用户或服务账号的角色进行更精确的资源访问控制。
在RBAC中,权限与角色相关联,用户通过成为适当角色的成员而得到这些角色的权限。
Role与ClusterRole
Role是一系列权限的集合,只能给某个指定的namespace的资源做鉴权。对于多namespace和集群级的资源或是非资源类的API(如:/healthz)使用ClusterRole。
Role示例:
kind: Role |
ClusterRole示例:
# ClusterRole 示例 |
RoleBinding和ClusterRoleBinding
RoleBinding:把Role的权限映射到用户或用户组,从而让这些用户继承角色在namespace中的权限。
ClusterRoleBinding:让用户继承ClusterRole在这个集群中的权限。
RoleBinding引用Role示例:
# This role binding allows "jane" to read pods in the "default" namespace. |
RoleBinding引用ClusterRole示例:
# This role binding allows "dave" to read secrets in the "development" namespace. |
k8s健康检查
LivenessProbe
Kubemetes可以通过存活探针(liveness probe)检查容器是否还在运行。可以为pod中的每个容器单独指定存活探针。如果探测失败,Kubemetes将定期执行探针并重新启动容器。
Kubernetes 支持三种方式来执行探针
| 探针类型 | 描述 | 成功条件 |
|---|---|---|
exec |
在容器中执行一个命令。 | 如果命令的退出码为0,则表示探测成功;否则表示失败。 |
tcpSocket |
对指定的容器IP及端口执行一个TCP检查。 | 如果端口是开放的,则表示探测成功;否则表示失败。 |
httpGet |
对指定的容器IP、端口及路径执行一个HTTP GET请求。 | 如果返回的状态码在 [200, 400) 之间,则表示探测成功;否则表示失败。 |

